For some reason, acquiring some unique skills and tweaks in your Linux operating system experience will positively boost your Linux administration resume and portfolio, especially for users involved in continuous projects.
One unique skill set to add to your Linux resume and portfolio is replacing whitespaces with tabs in a file.
If you are a programmer or a user that has had some exposure to various Linux-supported code editors, then you will relate to the frustrations of dealing with whitespaces.
Most coding guidelines have a preference for tabs over whitespaces. Popular code editors and IDEs are aligned to these guidelines and therefore will respond well to project files formatted with tabs over whitespace.
This tutorial will walk us through various approaches to getting rid of whitespaces in a file and replacing them with tabs.
Create Sample Reference File
A whitespace in a file can be both vertical and horizontal. In this tutorial, we will be mainly concerned with the horizontal whitespace characters.
We will create our sample file with horizontal whitespace characters which we will later try to remove through various methodologies we will cover.
$ sudo nano sample_file.txt
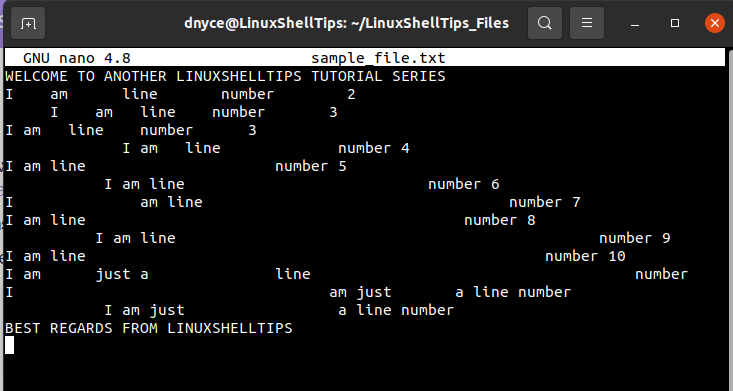
We can view this file with the cat command option --show-tabs to verify if any tabs exist within it.
$ cat --show-tabs sample_file.txt
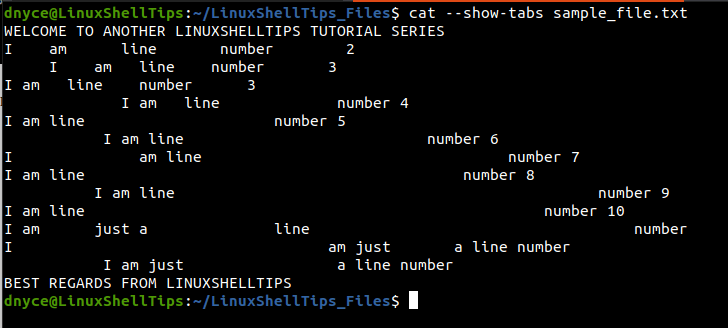
Our file is clean of tabs, as any tabs characters would be presented with the symbol ^I as the case with the following file:
$ sudo nano output.txt

You can view the above file with.
$ cat --show-tabs output.txt

We can now go over the various approaches to removing and replacing the horizontal whitespace characters from our file with tabs.
1. Using tr Command
The tr command is effective in cases where specific characters in a file need to be deleted or translated. In our case, we will be using it to convert the horizontal whitespace characters to tabs characters and then save the result to a random output file.
$ tr " " "\t" < sample_file.txt > new_sample_file.txt
We can then use the cat command to confirm that the tabs exist in the file.
$ cat --show-tabs new_sample_file.txt
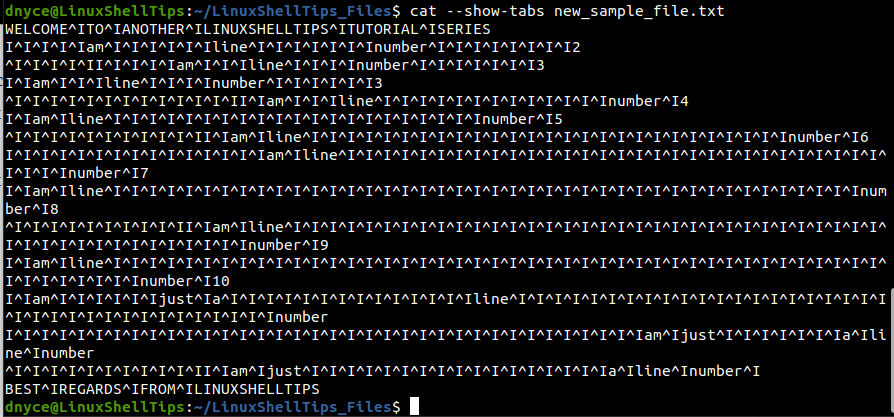
Each whitespace has been replaced with a single tab character. We can replace multiple whitespaces with a single tab when we use the -s option in our command.
$ tr -s " " "\t" < sample_file.txt > new_sample_file.txt $ cat --show-tabs new_sample_file.txt
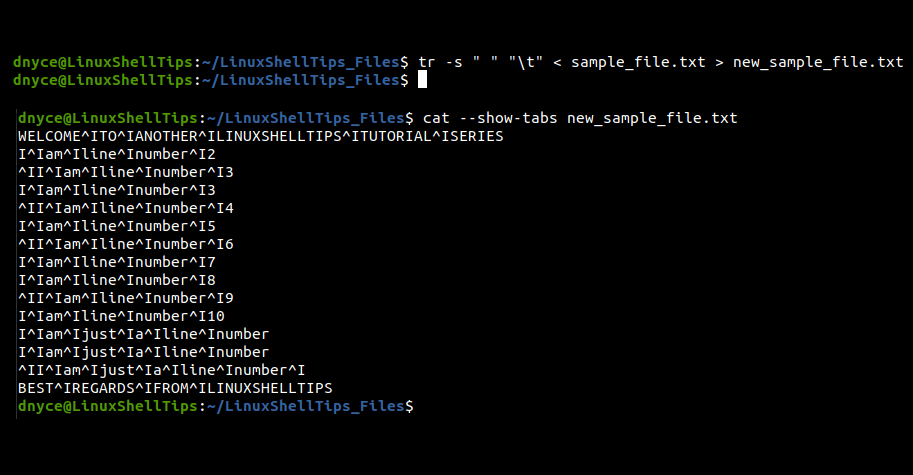
2. Using Awk Command
The awk programming language interpreter gained its reputation as a powerful and performant complex text processor. It is therefore an ideal alternative for converting whitespace characters to tab characters. It uses the -F option as field separator and OFS as the output field separator for the tab character.
$ awk -F'[[:blank:]]' -v OFS="\t" '{$1=$1; print}' sample_file.txt > new_sample_file.txt
Let’s use the cat command to confirm if tabs were created.
$ cat --show-tabs new_sample_file.txt
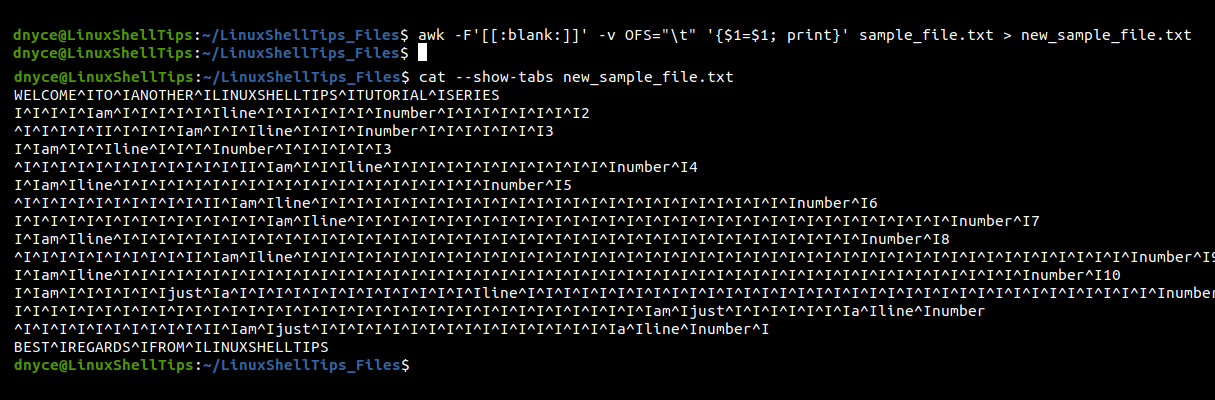
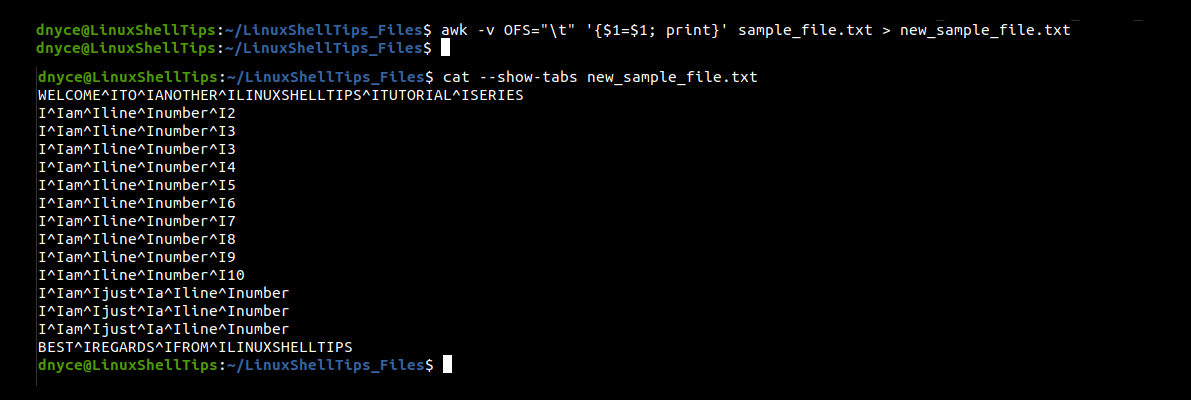
Removing the field separator -F will allow us to convert multiple whitespace characters to a single tab character.
$ awk -v OFS="\t" '{$1=$1; print}' sample_file.txt > new_sample_file.txt
$ cat --show-tabs new_sample_file.txt
3. Using sed Command
The primary role of the sed stream editor is to filter and transform text. To use it to convert whitespaces to tabs, we will implement it in the following manner.
$ sed 's/[[:blank:]]/\t/g' sample_file.txt > output.txt $ cat --show-tabs output.txt
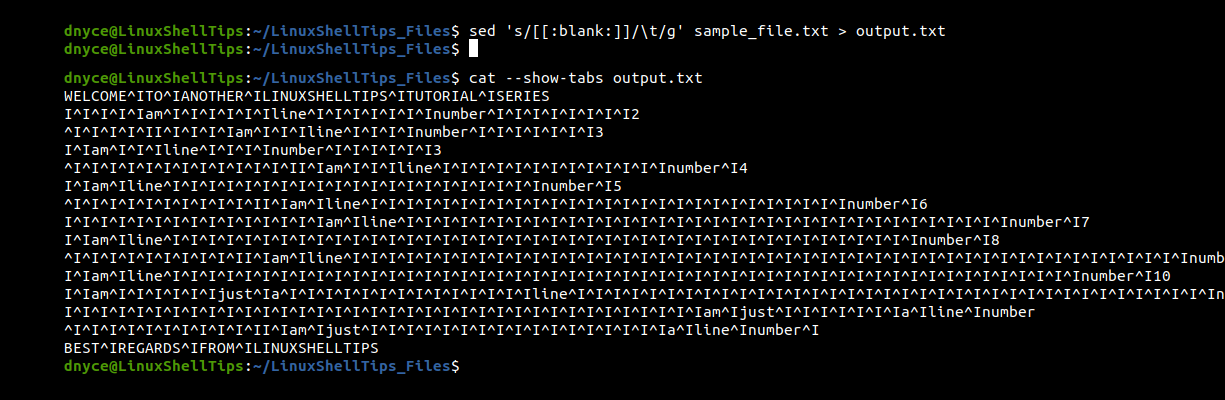
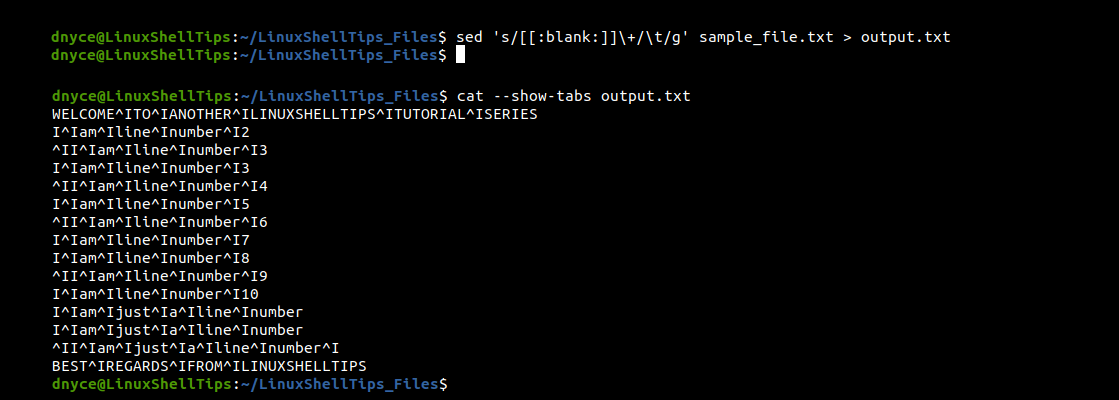
Adding an extended regular equation to the above sed command should help us convert multiple whitespace characters to single tabs characters.
$ sed 's/[[:blank:]]\+/\t/g' sample_file.txt > output.txt $ cat --show-tabs output.txt
We have successfully learned how to replace whitespaces with tabs in a file under a Linux operating system environment.