Before we take an in-depth tour of this article guide, we first need to understand what the article piece is trying to uncover. We need to understand or answer the question ‘why is it important to count files in Linux’. It is every Linux Administrator’s ambition to be familiar with the Ins and Outs of their operating system architecture.
Therefore, knowing the location and number of directory files you have to administer/manage is equally important. In this case, you could be having thousands of manually or automatically generated files by system users or programs and want to keep track of their increasing or finite number.
There are several inbuilt Linux-based commands that can easily help you in such circumstances. However, if we are looking for the fastest means of achieving this article’s objective, we have to be picky and considerate of other viable options.
Fast Way to Recursively Count Files in Linux
Few Linux commands stand out in terms of counting files recursively and fast. Let us compare the two most popular ones.
Linux’s Find Command Versus Locate Command
For demonstration purposes, we will be targeting the number of files inside the /home/user directory of the Linux operating system.
To get the speed difference between the find Command and locate command, we will associate their execution with Linux’s inbuilt time command so that we can figure out which approach of recursively counting files is faster.
Since the find command is already pre-installed on your Linux system, we only need to install the locate command before we initiate their execution speed comparison.
$ sudo apt-get install mlocate [On Debian, Ubuntu and Mint] $ sudo yum install mlocate [On RHEL/CentOS/Fedora and Rocky Linux/AlmaLinux] $ sudo emerge -a sys-apps/mlocate [On Gentoo Linux] $ sudo pacman -S mlocate [On Arch Linux] $ sudo zypper install mlocate [On OpenSUSE]
In reference to this article guide, the main locate command [OPTION] we are interested in is -c, -count since we are after a standard output that reflects a queried number of file counts.
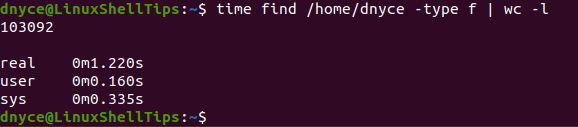
First, let us use the find command to count the number of files inside the /home/user directory. Your command should look somewhat similar to the following:
$ time find /home/dnyce -type f | wc -l
Second, let us see what results in the locate command will yield for counting files in that same /home/user directory. Its command implementation is as follows:
$ time locate -c /home/dnyce
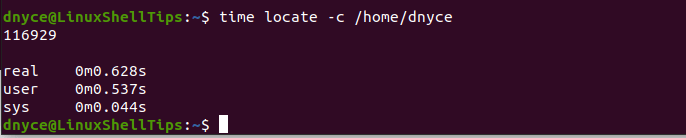
With the time command keeping track of the execution time of these two commands (find and locate), we can note that the locate command recursively dug deeper to produce more file counts in less time.
To use the Linux locate command, you must adhere to the following syntax rule:
$ locate [OPTION]… [PATTERN]…
By checking the locate command man page ($ man locate), you will also realize that this command can also be used for other viable file-related functionalities.
Also, even if we bring another popular command (ls command) to count files in a targeted directory, it will not be recursively deeper and faster to the level of the locate command.
$ time ls /home/dnyce | wc -l

The locate command is faster than the find command because its file count algorithm is database-oriented and not filesystem-oriented like its counterpart.
The default functional behavior of the locate command is to ignore the existence of the queried file(s) outside its database reach. Also, after a most recent successful database update on existing files, the locate command does not immediately report the creation of new files.