File management is an important aspect of Linux administration. You get to access and manipulate different user and system files based on availed access right privileges.
This article seeks to boost your Linux file management prowess by walking us through the steps needed to read/print a particular line from a file in Linux.
There is more than one approach to achieving this article’s objective. We are going to break down these approaches one by one.
Example Reference File
We will be referencing the following sample text file throughout this tutorial. Proceed to create the file with the following command:
$ sudo nano sample_file.txt
Populate the file with some lines of text from which we will be selecting random lines and printing them via relevant Linux commands.
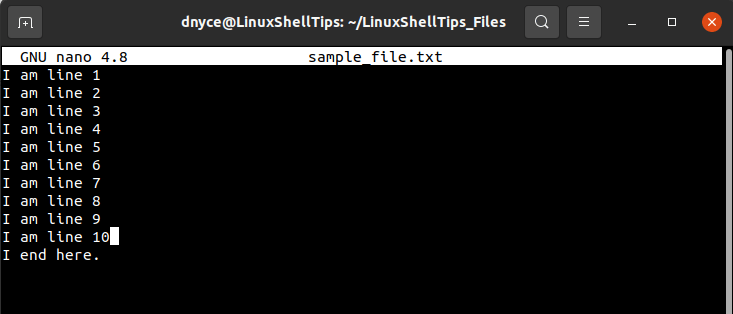
Let us use the cat command to view this file in a numbered view.
$ cat -n sample_file.txt
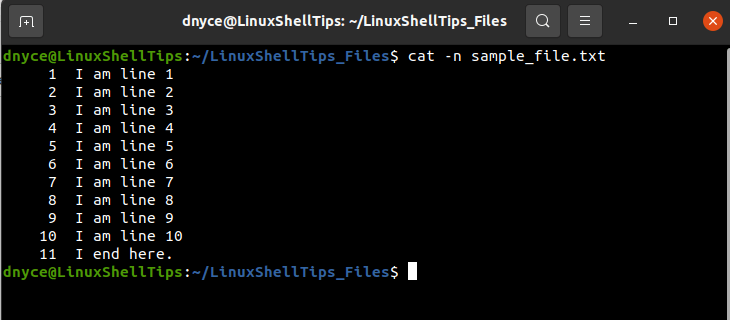
As per the above command output, we are dealing with a file that has 11 lines. We can now proceed and look at the available methods for printing/reading any of the above lines from the created sample_file.txt file.
1. Using Linux Head and Tail Commands
The head command on its own prints or outputs the first portion (usually the first 10 or so printable lines) of a text file to standard output.
The tail command on the other hand will output or print the last bit (usually the last 10 or so printable lines) of a text file to standard output.
Combining these two commands makes it possible to read/print a targeted text file line as demonstrated below:
$ cat sample_file.txt | head -5 | tail -1
The above command will read/print the 5th line (“I am line 5”) on the sample_file.txt file and print the output on our Linux terminal.

The cat command makes it possible to directly/interactively print the output of the above command execution of the terminal window.
2. Using the Linux sed Command
The default functionality of sed as described on its man page is to filter and transform text as a stream editor. It will take an input stream, filter, and transform it, before yielding the anticipated output.
There are two effective sed command approaches to reading/printing a particular line from a text file. The first approach utilizes the p (print) command while the second approach utilizes the d (delete) command.
A primary difference between these two commands is that the print command is associated with the -n option for indicating the text file line to print.
Using print with sed Command
We will print/read the third line (“I am line 3”) of the text file.
$ cat sample_file.txt | sed -n '3p'

Using delete with sed Command
We will print/read the seventh line (“I am line 7”) of the text file.
$ cat sample_file.txt | sed '7!d'

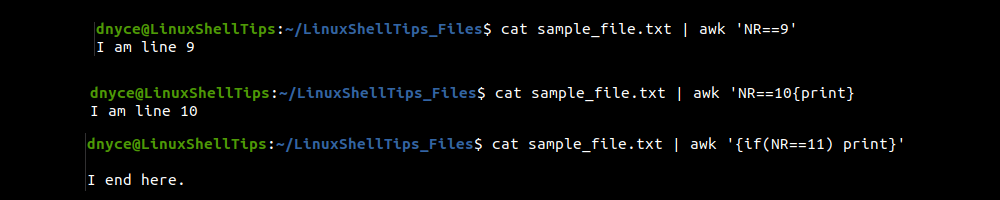
Using the awk Linux Command
The NR variable of the awk command keeps track of associated stream/file row numbers.
We can implement the awk command in three ways.
$ cat sample_file.txt | awk 'NR==9' [Prints 9th line]
$ cat sample_file.txt | awk 'NR==10{print}' [Prints 10th line]
$ cat sample_file.txt | awk '{if(NR==11) print}' [Prints 11th line]
This article has effectively familiarized us with practical approaches to reading/printing specific lines (texts or characters) from files in a Linux OS environment.