Archiving files is another important aspect of Linux file management, which helps in organizing and managing your project-related files and also saves on disk space to let your Linux OS accommodate more files and be more performant.
A common file archiving tool for seasoned Linux users is the GNU tar archiving program, which not only lets us store multiple files in a single file archive but also gives Linux users the privilege of manipulating the same archives.
This tutorial however seeks to explore the possibility of grepping an already existing tar.gz archive.
For this guide, we will not be interested in what the grep command has to offer since it primarily searches for a specific pattern within a normal input file as per its syntax reference below.
$ grep [OPTION...] PATTERNS [FILE...]
We will need a grep-versioned utility that handles compressed or archived files.
Problem Statement
For this tutorial to be interesting, let us create our own tar.gz archive using the Linux tar command. Consider the following root directory that has dir1, dir2, and systemlog.txt files.
$ tar czf dir_logs.tar.gz dir1 dir2 systemlog.txt
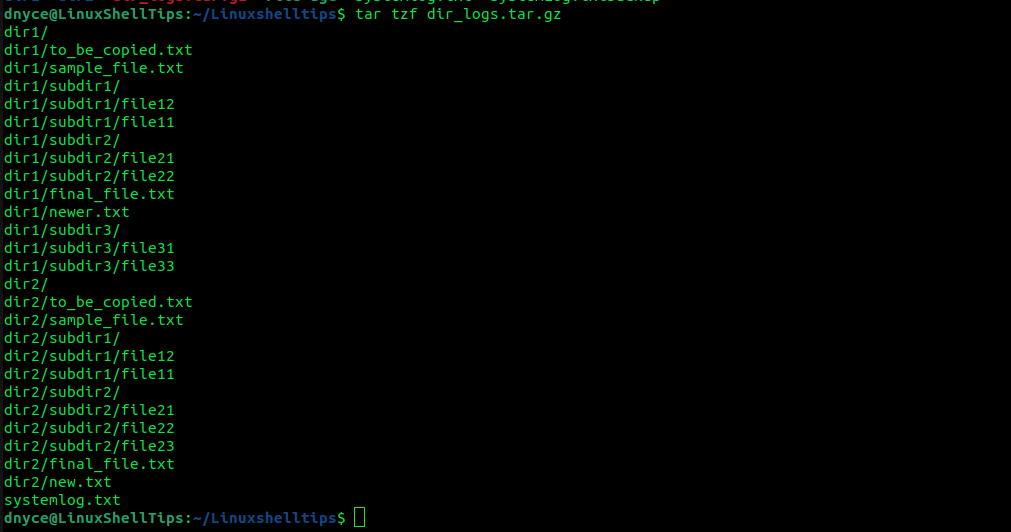
We should verify that the tarball was rightfully created.
$ tar tzf dir_logs.tar.gz
Now, for instance, let’s assume we have just downloaded this archive file from a network or the internet and want to query which of the files within this file archive contains a string entry like “Requested resource not found”.
A straightforward approach will be to first extract all the tarball files, individually grep search the extracted files, and finally retrieve the file with the matching info.
However, this solution is not real-world recommended as you might find yourself dealing with significantly bigger tar files with an infinite number of extracted raw files.
Querying such files individually for a string match might take an unreasonable time and even dramatically increase disk IO load. We need a way of searching the tar.gz archive without extracting all its files but only the file with the matched string search.
Using zgrep Command in Linux
As per its manual page (man zgrep), is a grep-based utility that can be used to query the contents of compressed/archived files based on a user-specified regular expression.
The zgrep solution to our problem of querying the string “Requested resource not found” in the dir_logs.tar.gz archive is as follows.
$ zgrep -Hai 'Requested resource not found' dir_logs.tar.gz

-Houtputs filename match.-aregards all binary files and text files.-iignores case distinctions.
Our queried string was found but as you can see, this solution does not retrieve the file associated with the queried string.
Let’s move on to another solution.
Using tar with –to-command Flag
To find the filename associated with the queried string match, we should first make it possible to extract these files to stdout to solve the extra disk IO loads issue. The --to-command option makes this approach possible.
Consider the implementation of the following tar command:
$ tar xzf dir_logs.tar.gz --to-command='grep --label=$TAR_FILENAME -Hi "Requested resource not";true'
We are able to grep the tar.gz archive ($TAR_FILENAME) for the string “Requested resource not” and retrieve the associated filename (-H) and ignore case distinctions (-i).

As you can see, we have been successful in getting a match to our searched string and also the filename associated with it.
We should be able to extract this one file we are interested in instead of the whole archive.
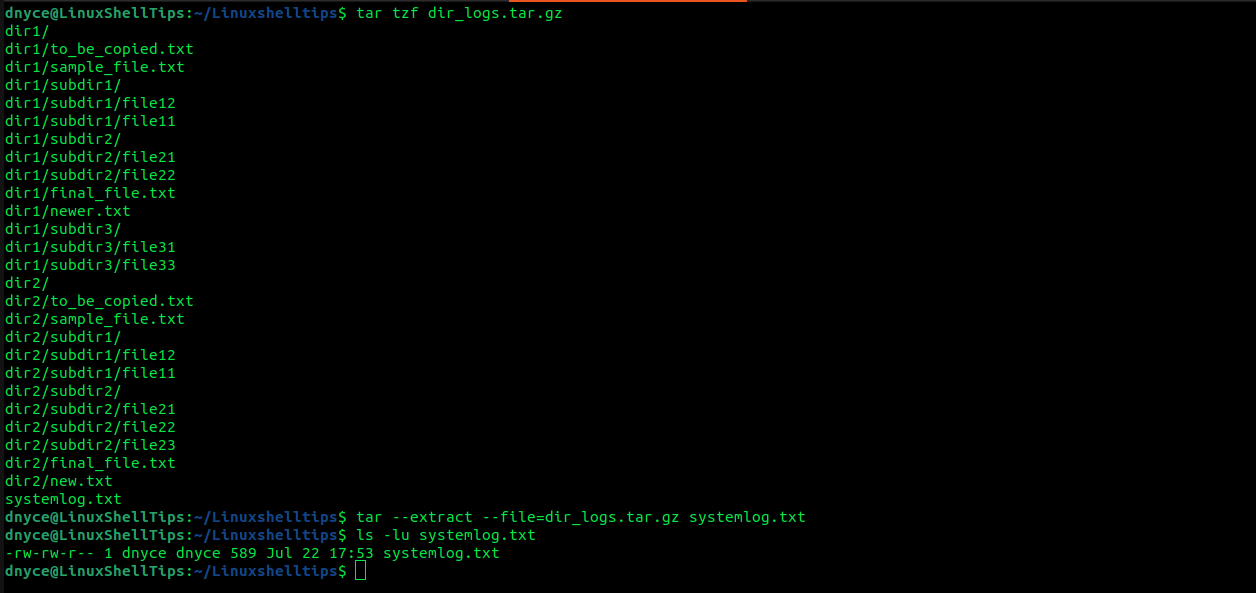
$ tar tzf dir_logs.tar.gz $ tar --extract --file=dir_logs.tar.gz systemlog.txt
The ls -lu command confirms the access time of the file we just extracted from the tar.gz archive.
$ ls -lu systemlog.txt
We should now be able to comfortably grep an tar.gz archive file in Linux. Hope this article was helpful. As always, your comments and feedback will be appreciated.