Once you enter the Linux operating system domain, the list of computing possibilities through the Linux command line environment will seem unending. It’s simply because the more you use Linux, the more you want to learn and this craving takes you through countless learning opportunities.
In this tutorial, we are going to look at counting and printing duplicate lines in a text file under a Linux operating system environment. This tutorial module is part of Linux file management.
The Linux command line or terminal environment is not new to processing input text files. It is so proficient in such operations that it is yet to encounter a worthy challenge under text file processing.
This tutorial will shed some light on identifying/handling duplicate lines within random text files in Linux.
Problem Statement
To make this tutorial easier and more interesting, we are going to create a sample text file that will act as the random file we want to check for the existence of duplicate lines.
$ sudo nano sample_file.txt
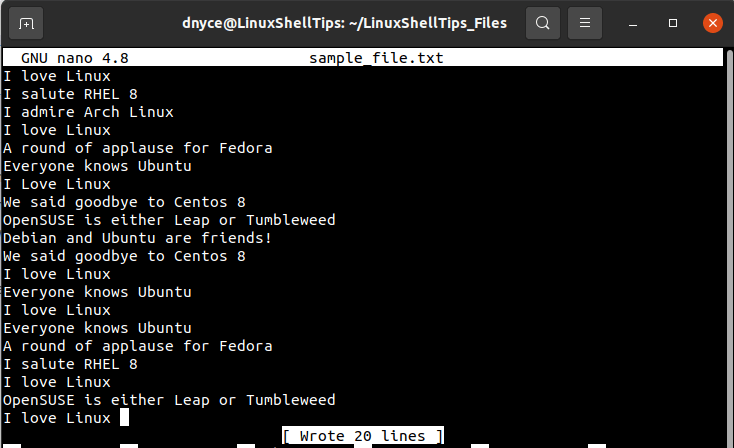
Just by scanning through the above text file’s screen capture, we should be able to note the existence of some duplicated lines but we cannot be certain of their exact number of occurrences.
To be certain of the number of duplicate lines occurring, we will find our solutions from the following Linux command-line/terminal-based approaches:
Find Duplicated Lines in File Using sort and uniq Commands
The convenience of using the uniq command is that it comes with -c command option. However, this command option is only valid if the text file you are targeting/scanning has duplicate adjacent lines.
To avoid this inconvenience while using the uniq command to print duplicated lines we have to borrow the sort command approach of grouping repeated/duplicated lines within a targeted text file.
In short, we will first pass the targeted text file via the sort command and afterward pipe it to the uniq command which will then be accompanied by the -c command option as demonstrated below:
$ sort sample_file.txt | uniq -c
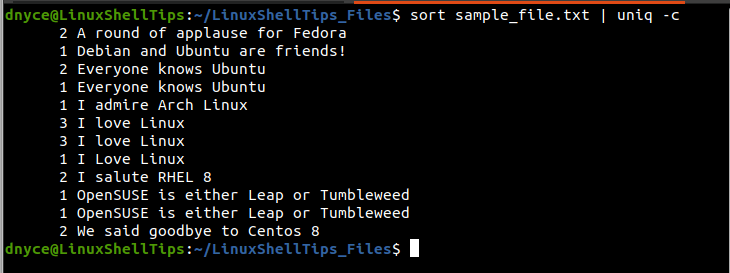
The first column (on the left) of the above output denotes the number of times the printed lines on the right column appear within the sample_file.txt text file. For instance, the line “I love Linux” is duplicated/repeated (3+3+1) times within the text file totaling 7 times.
Print Duplicated Lines in File Using Awk Command
The awk command to solve this “print duplicated lines in a text file” problem is a simple one-liner. To understand how it works, we first need to implement it as demonstrated below:
$ awk '{ a[$0]++ } END{ for(x in a) print a[x], x }' sample_file.txt
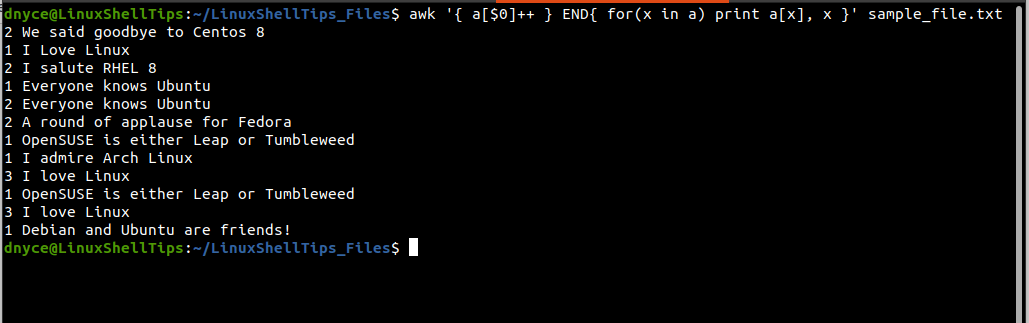
The execution of the above command outputs two columns, the first column counts the number of times a repeated/duplicated line appears within the text file, and the second column points to the line in question.
However, the output of the above command is not as organized as the one under sort and uniq commands.
We have successfully covered how to print duplicated lines in a text file under a Linux operating system environment.