As we have mentioned numerous times in the earlier article covered; whether directly or indirectly, it remains a valid statement that the computing depth of a Linux operating system cannot be matched with the strides of other operating systems.
Its open-source nature creates an unseen level of transparency for the end-users. While other operating systems provide the start button for baking a cake, Linux allows us to play with the cake ingredients as we move towards the final product.
This article will seek to explore the visible Linux-oriented steps for splitting a large text file into multiple smaller text files. This tutorial falls under the Linux file management segment.
One of the reasons why you might need to break a large text file into a smaller file is to meet set memory requirements. The large file might not fully fit in a removable media but splitting it makes it easy to transfer in bits.
Problem Statement
We will create a sample text file called large_file.txt to reference throughout this tutorial.
$ sudo nano large_file.txt
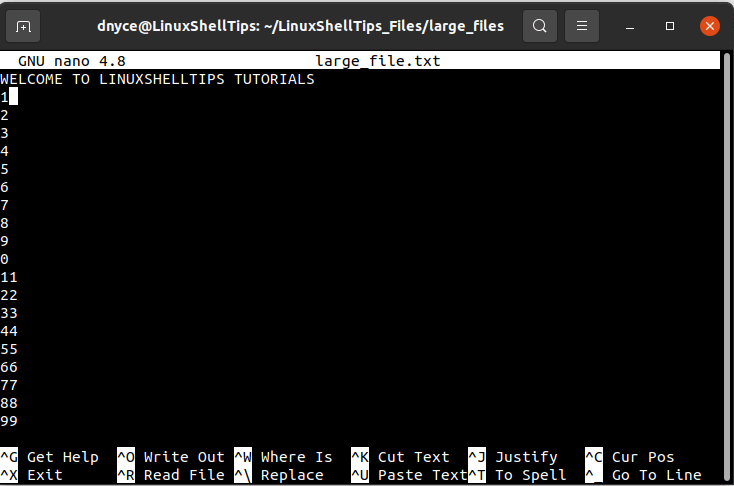
We are going to look at several useful Linux-based methodologies that will help us break the above large text file into multiple small text files. Smaller file transfers over a network are usually faster hence speeding up the network performance due to parallel transfers.
Using the Linux split Command
The split command is part of the GNU Coreutils package and primarily splits an input file into multiple smaller files.
The syntax for the usage of the split command is as follows:
$ split [OPTION]... [FILE [PREFIX]]
The split utility is associated with several useful command options as per its man page ($ man split). The default size of the file to split is 1000 lines. The split file takes a default suffix (x) and a default prefix (aa).
$ split large_file.txt
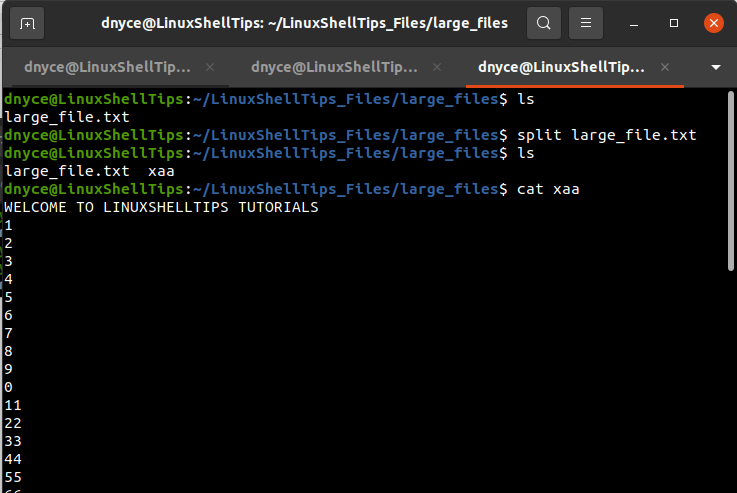
We only see one file split because the original text file has less than 1000 lines i.e. 49 lines, hence we logically created its duplicate.
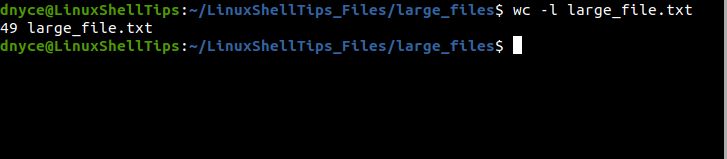
$ wc -l large_file.txt
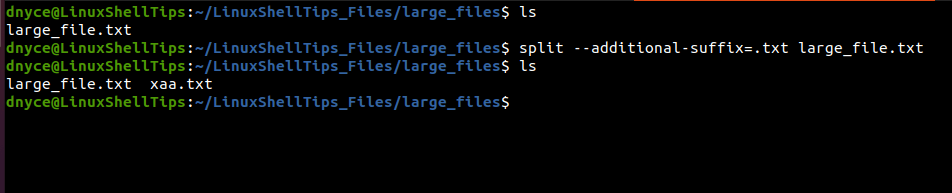
To retain the .txt file extension after file splitting, we will use the command option --additional-suffix.
$ split --additional-suffix=.txt large_file.txt
Splitting File by Specifying Number of Lines
Let’s say we want to split this large text file into smaller ones with 12 lines each, we will use the -l command option to specify the line number split we want.
$ split -l 12 --additional-suffix=.txt large_file.txt
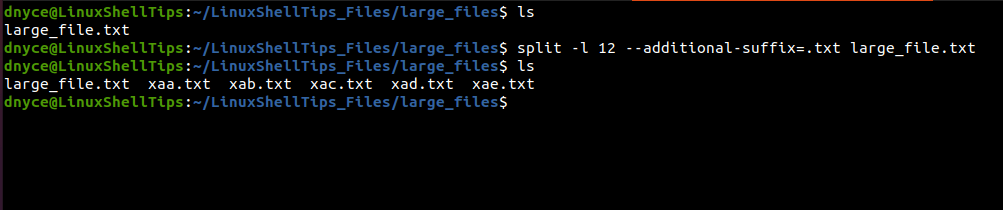
The 49 lined large_file.txt has been split into 5 smaller files each with a maximum of 12 lines.
$ cat xaa.txt | wc -l; cat xab.txt | wc -l; cat xac.txt | wc -l; cat xad.txt | wc -l; cat xae.txt | wc -l

Splitting File by Specifying Resulting File Sizes
Our file has a file size of 170 bytes.
$ ls -l large_file.txt

To split it into 30 bytes smaller files, we will use the -b command option.
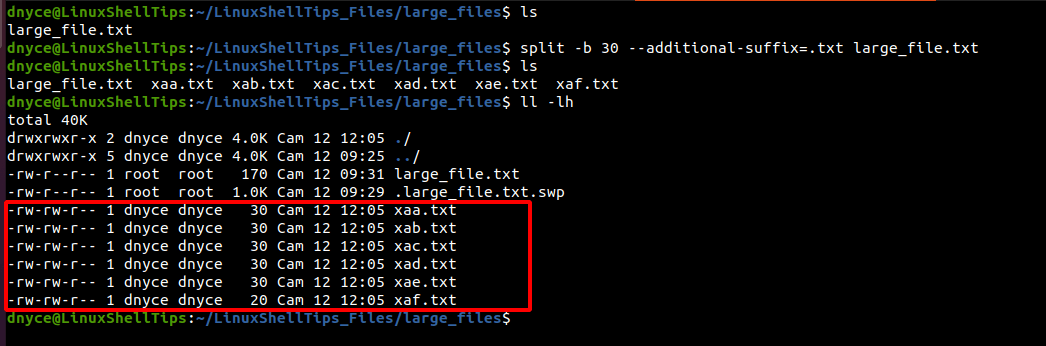
$ split -b 30 --additional-suffix=.txt large_file.txt
The command has generated 6 smaller files with a maximum file size of 30 bytes each.
$ ll -lh
Splitting File by Specifying a Prefix
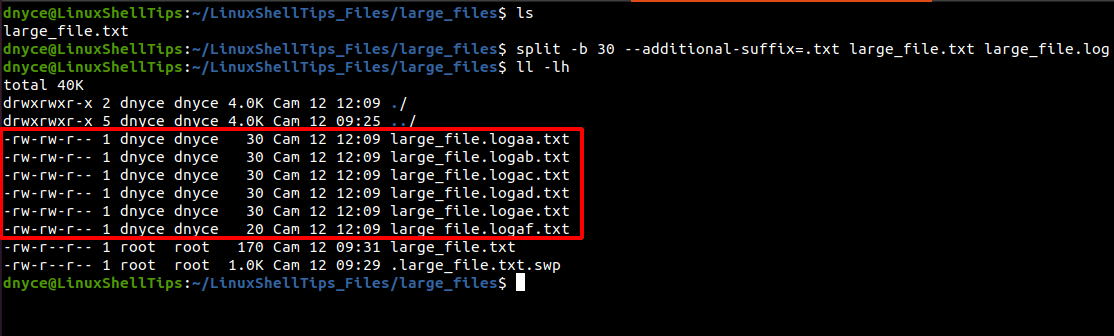
Let us for instance assume we need the 30 bytes split files above to have the prefix large_file.log, we would implement the following command.
$ split -b 30 --additional-suffix=.txt large_file.txt large_file.log
Splitting File by Using Numeric Prefix
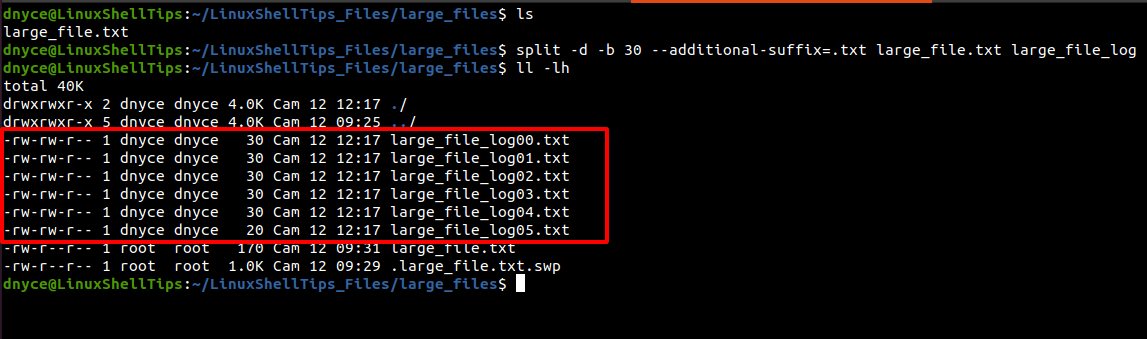
If you want the split files prefixes to be associated with numeric numbers like 00, 01, or 02 and not letters like aa, ab, or ac, implement the command with the -d command option.
$ split -d -b 30 --additional-suffix=.txt large_file.txt large_file_log
We can now comfortably split a large text file into multiple smaller files while retaining the .txt file extension in Linux.
I have a Question to split a big
.txtfile that is to be split and saved with the dynamic file names.input file:
aaaa
Start-KEYWORD(OutputFIleName1)
1a1a1a [1st file recrod start]
:
2a2a2a [1st file recrod ends]
end-KEYWORD.
Start-KEYWORD(OutputFIleName2)
3a3a3a [2nd file recrod start]
:
4a4a4a [2nd file recrod ends]
end-KEYWORD.
Start-KEYWORD(OutputFIleName3)
5a5a5a [3rd file recrod start]
:
6a6a6a [3rd file recrod ends]
end-KEYWORD.
:
etc..
Output should be – OutputFIleName1.txt.
1a1a1a [1st file recrod start]
:
2a2a2a [1st file recrod ends]
OutputFIleName2.txt
3a3a3a [2nd file recrod start]
:
4a4a4a [2nd file recrod ends]
OutputFIleName3.txt
5a5a5a [3rd file recrod start]
:
6a6a6a [3rd file recrod ends]
This needs to be done with shell scripts. Can anyone please suggest what to do.