You may ask yourself, why would a user be interested in noting/counting the number of columns in a file? This segment of our tutorial falls under Linux file management. A CSV (Comma Separated Value) file is a favorite file format for many Linux users for data record keeping because of the following advantages:
- You can use almost any text editor e.g. notepad to open and edit CSV files.
- CSV schema is relatively flat and simple hence applicable in data warehousing.
- You can use any programming language to generate and parse CSV data quickly.
- CSV does not manipulate stored data and clearly differentiates texts from numeric values.
- While other data recording file formats might require a start and end tag for each column created, CSV’s simplicity permits writing header columns only once.
- CSV is memory-friendly and faster to import.
- CSV mimics a simple text file hence easily to programmatically manipulate.
- CSV is human-readable.
This tutorial will walk us through viable approaches to counting the number of columns in a file that mimics the attributes of a CSV file.
Problem Statement
We need to have a sample CSV file for reference throughout this article. Therefore, consider the existence of the following CSV file.
$ nano sample_data.csv
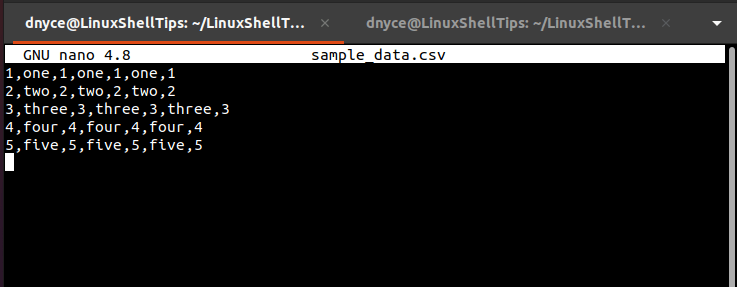
The file represented in the above screen capture assumes the attributes of a CSV file as each value/data on it is separated by a comma.
Using the head Command to Retrieve the First Row
Let us assume we are dealing with a file that has uniform columns. If the latter statement is true, then any of the rows from the above sample file should directly assist us in determining the total number of columns on it.
The excellent command to use here is the head command, which is a part of the GNU Coreutils package and should be available in almost all Linux operating system distributions.
The primary applicability of the head command is to retrieve the first part of a targeted file. Below is its usage syntax:
$ head [OPTION]... [FILE]...
To output the first row of our sample CSV file, we will run:
$ head -1 sample_data.csv

To output the first three rows of the CSV file, we will run:
$ head -3 sample_data.csv
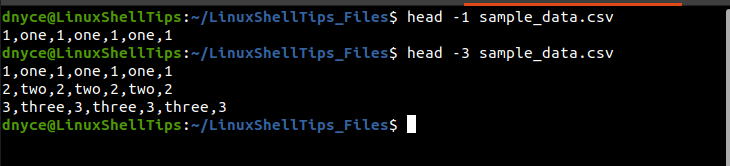
We are now ready to count the number of columns in this file:
Method 1: Using head + sed + wc Commands
The sed command is effective in filtering and transforming input-file text. Supposing we are dealing with the first row results from the head command we executed earlier, piping the head command result to the following sed command will ignore everything and only output the comma characters.
$ head -1 sample_data.csv | sed 's/[^,]//g'
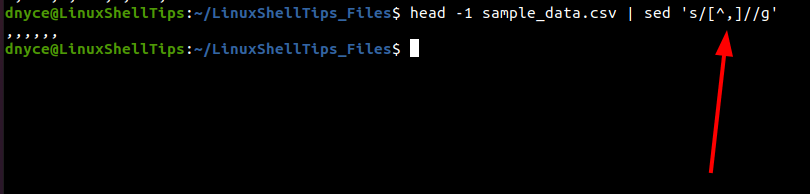
As you might have noted, the above command has outputted 6 commas. We will again pipe this output to the wc command which will count these comma characters plus the carriage (\n) character as the total number of columns.
$ head -1 sample_data.csv | sed 's/[^,]//g' | wc -c

We have successfully determined the number of columns on our CSV file as 7.
Method 2: Using head + awk Commands
The awk command is effective for scanning patterns of an input file. It is part of the Free Software Foundation package.
$ head -1 sample_data.csv | awk -F, '{print NF}'
The awk command option -F retrieves the field separators on the first row of the CSV file which is then printed as numeric (-N) characters by the command portion '{print NF}'.

With this guide, we can now comfortably count the number of columns in a file in Linux.
You might also like to read the following related articles: