As a Linux administrator or advanced user, mastering file management in whatever Linux operating system distribution you are using is paramount. File management is a core aspect of Linux operating system administration and without it, we would not be able to embrace file-related features like file encryption, file user management, file compliance, file updates & maintenance, and file lifecycle management.
In this article, we will look at an important aspect of Linux file management which is splitting large files into parts at given line numbers. If the objective of this article was just to split a large file into manageable small files without considering file line numbers, then all we would need is the convenience of the split command.
Sample Reference File
For this tutorial to make sense we will introduce a sample text file to act as the large file we wish to split from given line numbers. Create a sample text file and populate it as demonstrated.
$ sudo nano sample_file.txt
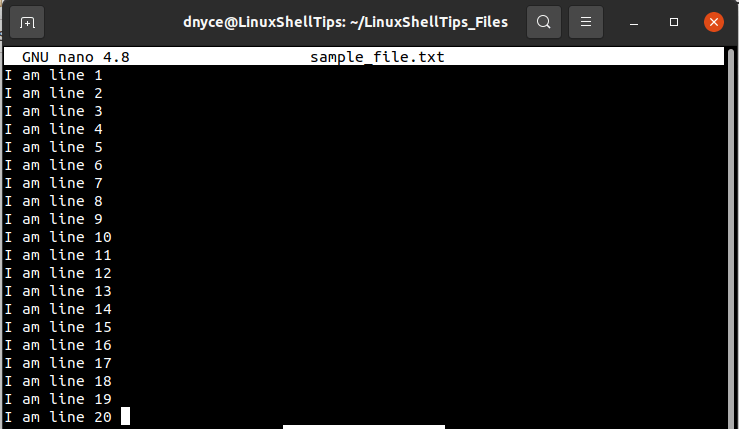
Open this file with cat command to note its associated line numbers:
$ cat -n sample_text.txt
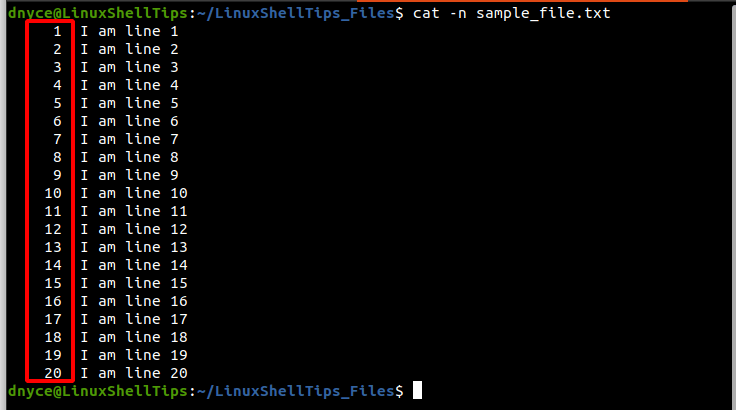
As you have noted, the above file has 1 to 20 line numbers. Now let’s say we want to split this file into 4 parts at line numbers 5, 11, and 17.
We would result with the following files:
- file_1 containing lines 1 to 5 of sample_file.txt.
- file_2 containing lines 6 to 11 of sample_file.txt.
- file_3 containing lines 12 to 17 of sample_file.txt.
- file_4 containing lines 18 to 20 of sample_file.txt.
Now that we have understood our problem statement, it’s time to look at the methodologies needed for a viable solution.
1. Using head and tail Commands
The effectiveness of combining these two commands to split a large file into parts from provided line numbers requires the inclusion of the -n option as part of its command execution.
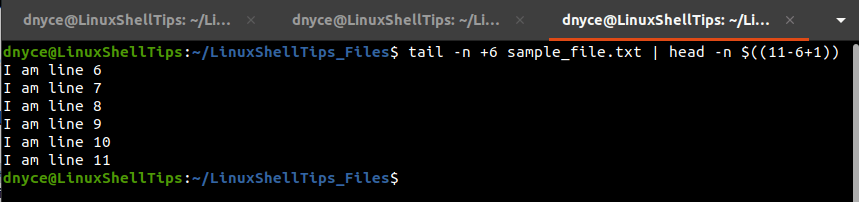
To extract line numbers 6 to 11, we will execute the following command.
$ tail -n +3 sample_file.txt | head -n $(( 11-6+1 ))
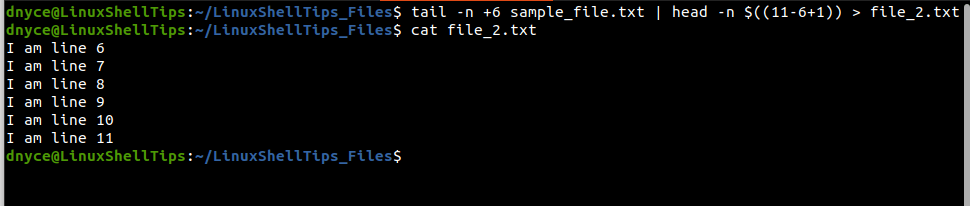
To save this output to file_2.txt:
$ tail -n +6 sample_file.txt | head -n $((11-6+1)) > file_2.txt $ cat file_2.txt
2. Using sed Command
Since the sed command supports two given address ranges, we can extract lines 12 to 17 in the following manner.
$ sed -n '12,17p; 18q' sample_file.txt

We can modify the command to save the above output to file_3.txt.
$ sed -n '12,17p; 18q' sample_file.txt > file_3.txt $ cat file_3.txt

3. Using awk Command
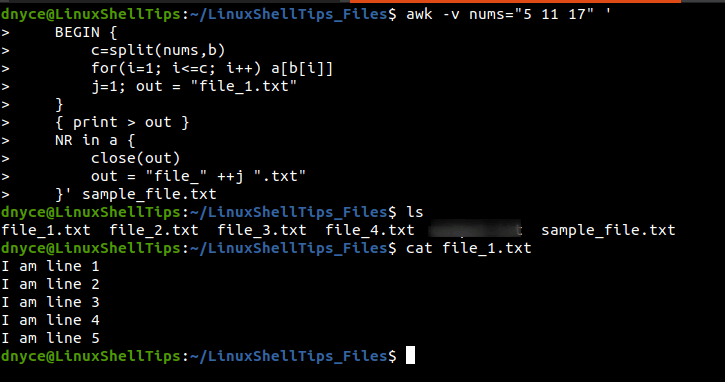
The awk command supports numerous features like redirection, loops, and arrays. Therefore, we can use it to create all the needed files parts (file_1.txt, file_2.txt, file_3.txt, and file_4.txt) from a large file (sample_file.txt) with one single command phrase as demonstrated below.
The awk command is provided with the key line numbers (5, 11, and 17) needed in splitting sample_file.txt into four parts (file_1.txt, file_2.txt, file_3.txt, and file_4.txt).
$ awk -v nums="5 11 17" '
BEGIN {
c=split(nums,b)
for(i=1; i<=c; i++) a[b[i]] j=1; out = "file_1.txt" } { print > out }
NR in a {
close(out)
out = "file_" ++j ".txt"
}' sample_file.txt
The outcome of executing the above awk command is evident in the following screen capture.
We can now comfortably split large files into parts based on provided line numbers through various approaches as covered in this tutorial piece.
You might also like to read the following related articles: