The need for file comparison on a Linux operating system is often overlooked but has an important role to play especially for Linux system administrators. Being able to flexibly compare two files on a Linux terminal sheds some light on how unique or different a set of files are perceived to be.
[ You might also like: How to Join Two Text Files in Linux ]
For example, two files can exist with the same properties and size. Instead of making the assumption that they are identical, a Linux file comparison program will clear the air on such an issue. You could be surprised to find out that the differentiating factor of the two files is some wording or spacing that matches with one file and fails to do so with the other one.
Several terminal-based Linux programs can help us achieve the objective of this article but only a few stand out in terms of dynamic functionalities.
Creating Text Files in Linux
Let us create two sample files from the Linux terminal. Ensure that you are a sudoer user or have sudo privileges on the Linux operating system you are using.
$ sudo nano file1
We will populate this file with some random content.
1 2 3 4 5 6 7 8 9 10 one two three four five six seven eight nine ten This file contains some number sequences in numeric and textual form. Regards, LinuxShellTips Tutor
Let us create a second file.
$ sudo nano file2
We will populate this file with content slightly similar to file1.
11 2 13 4 15 6 7 8 19 10 one twice three four five six seven eight nine ten This file contains some number sequences in numeric form and some textual representation of the numbers. Regards, LinuxShellTips Tutor
Using diff to Compare Files in Linux
Since diff is a terminal-based program, using it outputs the targeted differences between two files. In other words, the diff output tells you the changes that can be implemented on file1 to make it a match or identical to file2.
Outputting the Differences between Two Files
Let us implement the first attempt into comparing these two files:
$ diff file1 file2
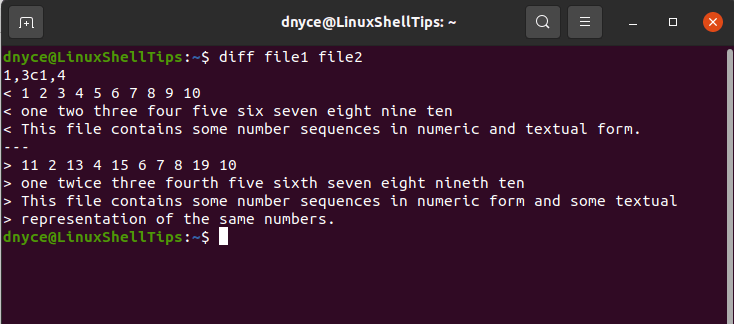
We can interpret this output in the following manner:
If you go back to the original file1 and file2 files we created earlier, you will note that the above diff command output is not displaying all the content from the two files. It has omitted all the similarities of the two files and only displayed their differences.
Find Out Two Files are Identical Using Diff in Linux
Let us create a third file called file3.
$ sudo nano file3
We will populate this file with content similar to file1.
1 2 3 4 5 6 7 8 9 10 one two three four five six seven eight nine ten This file contains some number sequences in numeric and textual form. Regards, LinuxShellTips Tutor
A one-liner diff command output should be able to directly tell us if two files are identical.
$ diff -s file1 file3

The use of the extra -s command argument makes this output possible. However, implementing it with two unidentical files will still output their differences.
$ diff -s file1 file2
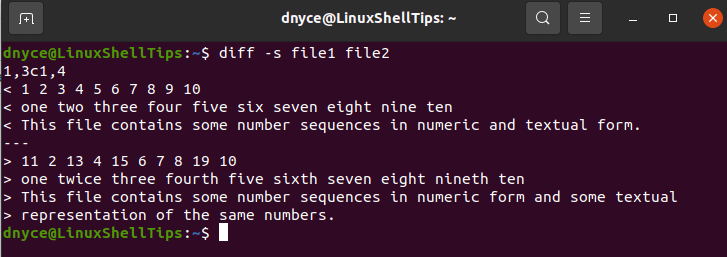
If you are looking for a one-liner output on two files you suspect to be different, consider the use of the diff command with the -q option.
$ diff -q file1 file2 Files file1 and file2 differ
Diff Command Output Alternate View
If you need the output comparison of your two files to be side-by-side, consider implementing the diff command with the -y option.
$ diff -y file1 file2

If you want the above command to suppress or ignore the similarities of the two files, include the --suppress-common-lines option.
$ diff -y --suppress-common-lines file1 file2
If you are dealing with two large files and want to limit the output to specific column numbers, you would implement the diff command in the following manner.
$ diff -y -W 50 file1 file2
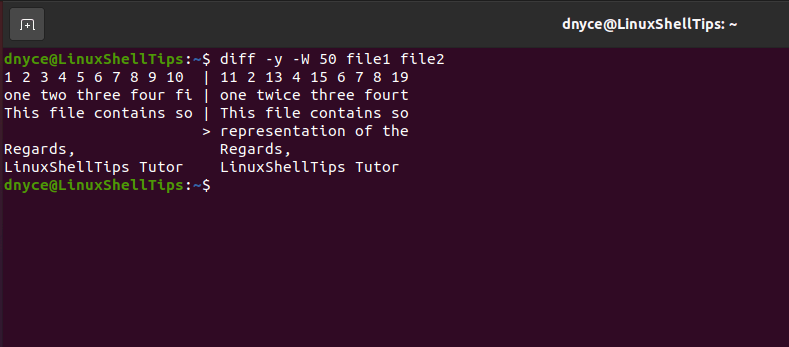
The above command assumes the two files in comparison are somewhat large and exceed 50 columns in terms of text size. The diff output will be limited to 50 columns.